Decision trees are simple to understand. Yet they are the basic element of many powerful Machine Learning algorithms such as Random Forest. This serie of blogs will introduce the concept of decision tree and also provide basic scala code for those who want to better understand as well as do some experiments.
Binary decision trees
A binary decision tree is a model that predicts a result by checking multiple assertions. For example, this is a very simple binary decision tree taking as input a real value :

true
-----: 1
true |
------------ x>5?
| | Example (1)
x --- x>0? -----: 0
| false
-----: -1
false
The prediction of such a decision tree is:















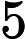

A binary decision tree is made of leaves and nodes. The leaves provide the predicted values. The nodes allow branching. Each node needs to keep the following information: a test function, and to which node or leaf to go next depending on the result of the test.
The simplest non-empty decision tree is made of one leaf. It always provides the same result whatever the input is.
Example (1) has three leaves with associated values -1, 0 and 1, and two nodes that test if x is positive or greater than 5:
----[leaf3: 1]
|
true
|
-----------[node2: x>5?]
| |
true false
| |
x -----[node1: x>0?] ----[leaf2: 0]
|
false
|
----[leaf1: -1]
/** The building blocks of a binary decision tree being leaves and nodes,
* we create two Scala classes Leaf and Node that extend a trait DecisionTree.
*/
trait DecisionTree[-A, +B] {
def predict(sample: A): B
}
/** A leaf is a simple element that provides a prediction value (or decision). */
case class Leaf[A, B](decision: B) extends DecisionTree[A, B] {
def predict(sample: A): B = decision
}
/** A node stores a test function as well as to which node or leaf to go next depending on
* the result of the test.
* We define as:
* - *right* the leaf or node to go to when the test is true,
* - *left* the leaf or node to go to when the test is false.
*/
case class Node[A, B](test: A => Boolean, left: DecisionTree[A, B], right: DecisionTree[A, B])
extends DecisionTree[A, B] {
def predict(sample: A): B = test(sample) match {
case true => right.predict(sample)
case false => left.predict(sample)
}
}defined trait DecisionTree
defined class Leaf
defined class Node
We now build the decision tree of Example (1), evaluate it at three different points and check that the result is the expected one. We keep the previous numbering of nodes and leaves:
val leaf3: Leaf[Double, Int] = Leaf(1)
val leaf2: Leaf[Double, Int] = Leaf(0)
val test2: Double => Boolean = _ > 5
val node2: Node[Double, Int] = Node(test2, leaf2, leaf3)
val leaf1: Leaf[Double, Int] = Leaf(-1)
val test1: Double => Boolean = _ > 0
val node1: Node[Double, Int] = Node(test1, leaf1, node2)
val tree: DecisionTree[Double, Int] = node1
// Let's test a few values:
(tree.predict(-2), tree.predict(0.5), tree.predict(9)) == (-1, 0, 1)true
We previously detailed every step of the construction of the decision tree, but it could have been simply written as:
val tree: DecisionTree[Double, Int] = Node(_ > 0, Leaf(-1), Node(_ > 5, Leaf(0), Leaf(1)))
// Let's test a few values:
(tree.predict(-2), tree.predict(0.5), tree.predict(9)) == (-1, 0, 1)true
We saw in this part how to build a simple binary decision tree in Scala. In Part 2, we will see how to create a simple class to handle the samples and labels of a data set.